-
Tell us a little bit about yourself.
I am originally from Colombia and I have been living in Berlin for the past 6 years. I moved here because I wanted to be a data scientist. I had experience working with databases and a sound knowledge about Statistics, as my major was in Industrial Engineering, therefore, I saw this as the natural path for me. I finished my masters in Data Science in 2018 and I have been working in Machine Learning since then. Initially, I worked with NLP, my last project (reciprocal recommenders) involved Graph Neural Networks, so now I am into graphs. I love what I do, it makes me happy knowing people are using what I help to build.
-
How did you first become involved in open source? In what ways? What has been your experience contributing to open source prior to the Data Umbrella PyMC Sprint?
I have been trying to contribute to different projects, but it’s not always easy. Your questions or comments are not answered and you feel frustrated. I have got some small PRs merged in some projects which gave me a lot of satisfaction. It feels good to know that a piece of your code will be used by thousands, if not millions.
-
How did you learn of the Data Umbrella PyMC sprint and what inspired you to attend?
I joined the sprint because I have heard recently about Data Umbrella and I really liked the concept, I checked their website and I found the PyMC sprint. I haven’t used PyMC much before the sprint. I only tried it once a year ago while I was reading the Statistical Rethinking book, but I have never used the library for a real project. That’s the value the Data Umbrella sprints bring, you don’t need to know the code base of a project to participate and they carefully planned different webinars to bring you up to speed. Apart from that, the social component is very appealing; when I tried to contribute before, I was alone in the process. In a Data Umbrella sprint, there are not only volunteers to help you, but also other people like you wanting to contribute and experiencing similar doubts.
-
What was your experience contributing to open source at the Data Umbrella PyMC Sprint?
In the webinars I attended, people were very welcoming and they answered every question from the audience. I would say Data Umbrella does a great job in creating a safe space. Specifically in this sprint, the volunteers from the PyMC team put a lot of thought and effort creating detailed tutorials to get you started. They had also pre-selected issues that a newbie could solve.
-
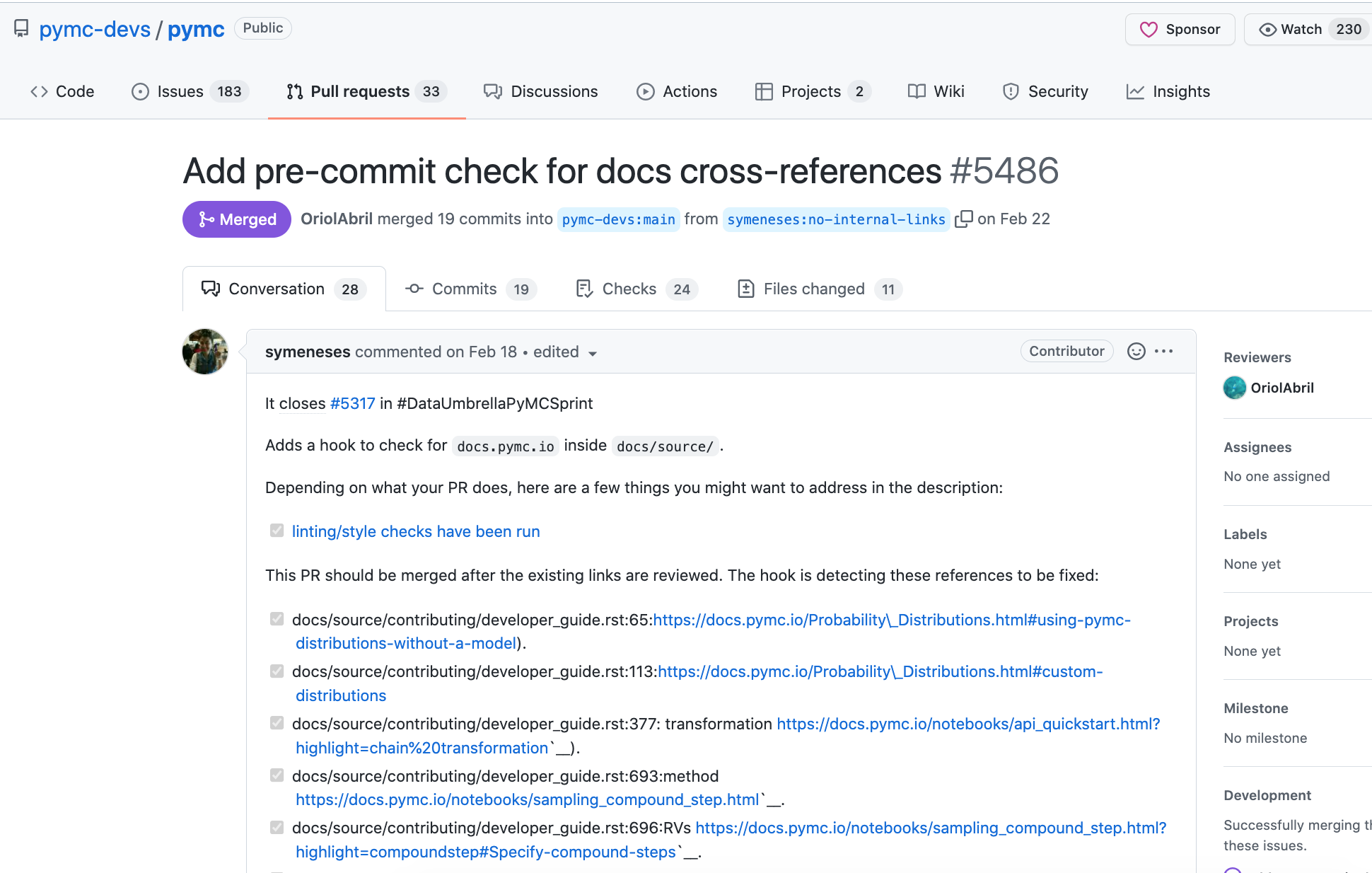
How did you begin work on this PyMC issue #5317?
As I didn’t know the code base of the project and I haven’t used PyMC extensively, I looked for a “maintenance” issue, then I looked for issues related to the CI/DC, containers, images, etc. Then I found an issue about pre-commit and I thought this is my chance to serve two purposes at the same time, to contribute and to learn something new. I have heard about pre-commit but I hadn’t used it, as it was marked as beginner friendly then it shouldn’t be difficult, I thought. I checked the pre-commit docs and the pygrep hooks and I found how to create the check. After that, I could create the PR, but there was a catch: there were many files that needed to be fixed and I didn’t know much about Sphinx, fortunately as the contribution was part of the sprint, the PyMC volunteers helped me to understand how to fix all the references.
-
What were the benefits of participating in the sprint?
There are multiple benefits:
- Having a safe environment so that beginners can ask any question.
- Having issues pre-selected for us helped to find issues that are feasible to be solved in the given time.
- I could see the PR merged really fast, as we had PyMC contributors available at the moment, which gives immediate satisfaction.It’s highly recommended for anyone to join a sprint, no matter what your background is or your skills, you will learn something new and find nice people on the way. I am really thankful for all the work Data Umbrella is doing to organize the sprints.
-
What, in particular, makes Data Umbrella and the sprints welcoming and accessible for you?
I think Data Umbrella events feel accessible because the code of conduct is always mentioned in the beginning. It may sound repetitive and unnecessary but unfortunately we still need to remind people how to behave and to show that there are things that are not okay. On the other hand, I have attended ML/Tech conferences and in many of them, I get the feeling that I am treated accordingly to my role, the company where I work or at which levels my skills are, which has somehow bothered me, because I think every person is valuable, not a connection or a tool to position yourself. That’s not the case in Data Umbrella, you are not labeled and there is no “networking” time.
-
What do you find about open source that is alluring?
We have built impressive things thanks to collaboration. It’s almost a premise that money is the only way to distribute resources and we need the economic system to create big things, like the internet, phones, computers, rockets, etc. Open source or Wikipedia is proof that we humans can get together to build great things without an economical reward. Unfortunately, many use open source projects to make profit and don’t give back to the community, but I hope that’s an exception and not the rule.
-
What advice do you have for folks in the community who are new to open source?
The best way to start is to find a project that you use and see how active its community is, how often there are releases. Get engaged with its community, most projects have forums, Slack or Discord channels, and see how welcoming they are. It’s important to have a good experience in the beginning to look for a project where you feel comfortable. Once you find a project, see issues that are simple and don’t be afraid to open a PR, it doesn’t have to be perfect. Say explicitly that you are new and that you may need help.
-
What are your favorite resources (books, courses, conferences, events, communities, etc.)?
Whenever I want to dig deeper into a topic, I buy books related to the topic. For practical knowledge, I generally take courses. I have used most platforms: Coursera, Udemy, freeCodeCamp.org, YouTube channels, etc. Right now I am learning Knowledge Graphs following this course.
-
What are your hobbies, outside of work and open source?
I enjoy reading about different topics: Economics, Psychology, Philosophy, Biology, Physics, etc. I am not an expert in any topic, but I can have a good conversation about any topic, so that’s my second hobby, talking with people. And the last one, again related to my curiosity is to travel and see how other people live and experience every place like a local, discovering what is special in it.
-
Anything else you would like to share?
I left my paid job recently to be the creator of useful and beautiful products. If you have some ideas on how I can help an open source project with my skills (see my LinkedIn Profile), just let me know.