
Author: Reshama Shaikh
High Level Summary
- 40 participants
- 23/40 (57.5%) Returning contributors; 17/40 (42.5%) New contributors
- 17 countries represented
Sprint Background
This sprint was organized by Data Umbrella to increase the participation of underrepresented persons in data science, with a focus on the geographic regions of Africa & the Middle East (AFME).
The “sprint” is a hands-on hackathon where participants learn to contribute to scikit-learn, the most widely-used Python open source, machine learning library. This sprint was a 4-hour block of time with pre- and post-sprint work required.
This report focuses on the summary, impact and lessons learned of the Data Umbrella AFME2 scikit-learn sprint.


Event Sponsor
This event was funded in part by a grant from Code for Science & Society, made possible by grant number GBMF8449 from the Gordon and Betty Moore Foundation.
Sprint Agenda
- 09-Oct-2021: Pre-sprint Kickoff (10am - 11am ET) (14:00 UTC)
- 23-Oct-2021: Sprint (10am to 2pm ET) (14:00 UTC)
- 06-Nov-2021: Sprint Follow-up Office Hours (10am to 11am ET) (14:00 UTC)

Sprint Day
The sprint officially ran 4 hours, which is limited time to submit a PR. The participants continued to work on their sprint PRs throughout the weekend.
Follow-up Office Hours
Office hours were set up 2 weeks after the sprint where some of the scikit-learn core contributors were available to answer questions on open PRs.
Number of Attendees
- Pre-sprint Event: 9 people
- 2 organizers
- 4 core developers
- 9 participants (6 returning; 3 new)
- Sprint Day: ~40 people
- 3 organizers
- 4 core developers
- 40 participants (23 returning; 17 new)
- Post-sprint Office Hours: 7 people
- 1 organizer
- 2 core developers
- 7 participants (2 returning; 5 new)
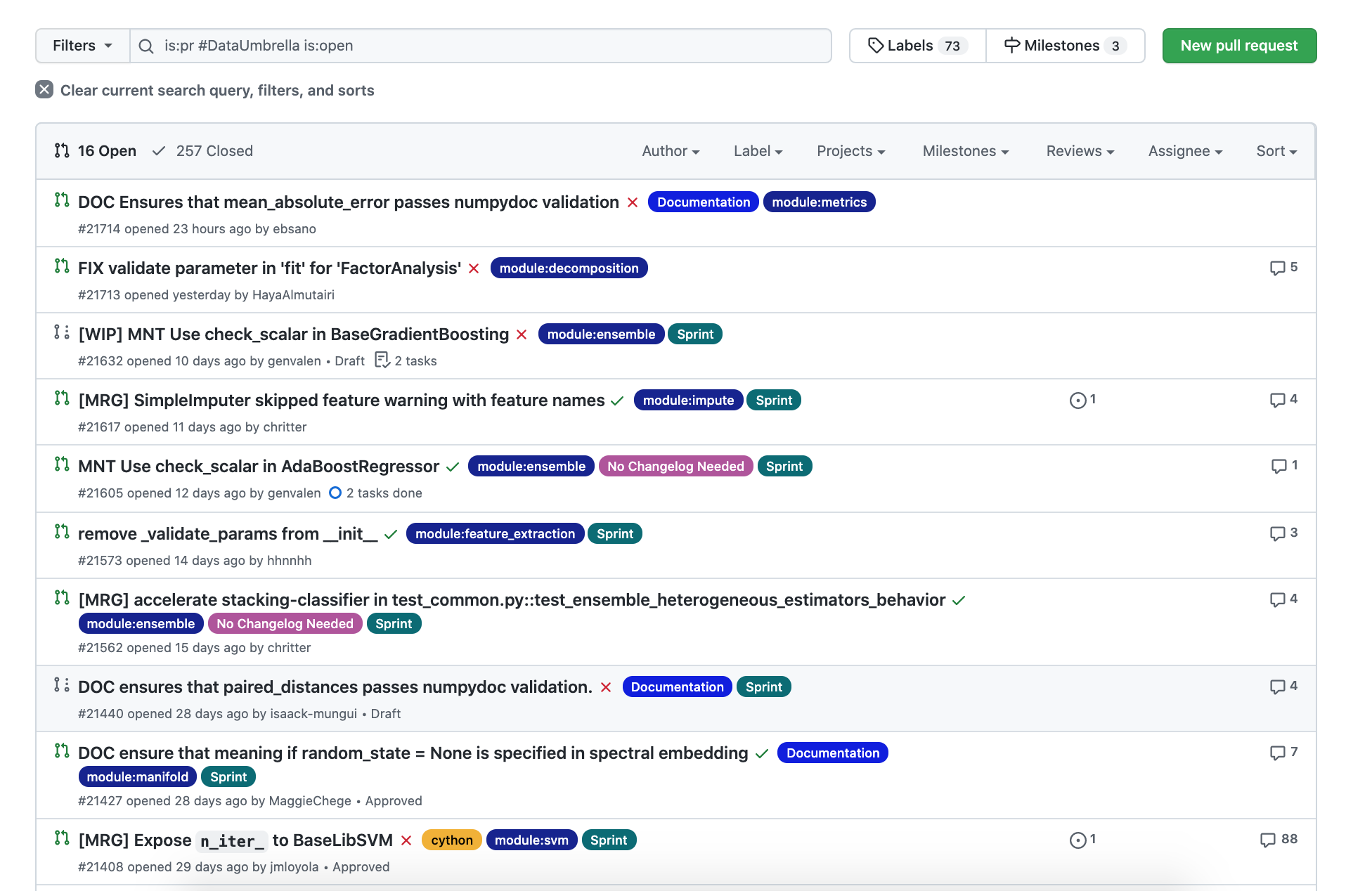
Pull Requests (PRs) Statistics
- 7 PRs were merged on sprint day
- 7 additional PRs were merged within 2 days of sprint day
- 33 PRs: a total of 33 PRs have been merged in the 4-week period of sprint day to date of report.
As of the date of this report (20-Nov-2021), there are 16 PRs open. Participants continued work on new issues after the sprint.
is:pr #DataUmbrella is:open
Demographics
Of the 74 people who applied, 40 attended. All applicants were accepted. This funnel graph shows the breakdown, by gender.
A total of 40 contributors attended the sprint. 14 of 40 (35%) identified as she/her. 26 of 40 (65%) identified as he/him.
Contributors joined from 17 different countries. Country information was provided based on where participants were joining from. The countries with the most participants:
- Kenya: 11
- United States of America: 5
- India: 4
- Saudi Arabia: 2
- Germany: 2
- Canada: 2
- Bulgaria: 2
- Argentina: 2
Other countries with 1 participant each include: Zambia, Venezuela, Sweden, South Africa, Poland, Lithuania, Kazakhstan, Ireland, Ghana, El Salvador.
Invited Contributors
There were 4 invited contributors. Invited contributors were those who participated in a prior sprint and have continued contributing to scikit-learn.
Returning Contributors
This pie chart shows that of the 40 people attending, 57.5% were returning contributors.
Applications Received
This barplot shows all the countries from which applications were received. It also shows a breakdown of how many people attended from each country.
Spoken Languages
The sprint was run in English. Participants were asked on their forms to indicate if they needed a translator. No translators were requested.
This barplot shows the primary spoken languages by the sprint participants.
Attendee Role (work/school)
Impact Report for Data Umbrella Scikit-learn Sprint
| Sprint 2021 | ||
|---|---|---|
| Report date | 20-Nov-2021 | |
| Report author | Reshama Shaikh | |
| Sprint date | 23-Oct-2021 | |
| Location | Online; Africa & Middle East (AFME2) | |
| Sprint website | afme2021rc.dataumbrella.org | |
| Moment | ||
| Open source library | scikit-learn | |
| GitHub repository link | data-umbrella/data-umbrella-scikit-learn-sprint | |
| Lead Organizer | Reshama Shaikh | |
| Assistant Organizers | Mariam Haji, Cristina Mulas Lopez, Nestor Navarro | |
| Lead Facilitator | Andreas Mueller | |
| Mentors / Translations | Not applicable | |
| Scikit-learn core contributors | Thomas Fan, Adrin Jalali, Olivier Grisel, Julien Jerphanon, Guillaume LeMaitre | |
| Teaching Assistants | None | |
| Community Contributors | Lucy Jimenez, Juan Martin Loyola | |
| Platforms | Discord & Zoom | |
| Sponsor: | Grant GBMF8449 from Gordon and Betty Moore Foundation & Code for Science and Society | |
| PULL REQUESTS (PRs) | ||
| PRs [MRG] at sprint | 7 | |
| PRs [MRG] post-sprint | 26+ (x) | |
| PRs open | 16+ | |
| Attendees: Initial Registrations | ~55 | |
| Attendees: Participated | ~40 | |
| Attendee List | Sprint Contributors | |
| Post-sprint Survey | [survey form] (closed) | |
| Blog 1: Beryl Kanali | My experience contributing to Open Source -AFME2 Oct 2021 |
Resources for Contributing to scikit-learn
Because this was a virtual event and there is a limited capacity for being online for a full 8-hour day, a checklist was provided so folks could do preparation work at their own pace prior to the sprint. Resources for Prep Work are available on the sprint website.
A Checklist with highlighted notes to indicate updates from videos was also included.
Impact
Non-measurable Impact
Aside from the number of PRs that were merged, there is non-quantifiable impact of the open source sprint. Some examples include:
- learning to set up virtual environment
- using Git (fork, clone, branch, fetching another’s PR)
- introduction to tests such as: flake8 (linting, formatting), pytest, “continuous integration”
- navigating through the codebase structure of scikit-learn
- digging into functions, learning about errors
- learning about unit tests
- interacting with contributors on GitHub
- learning, in general
- networking
- building confidence (making a dent in “imposter syndrome”)
- having fun
Challenges
Challenge 1: Outreach
Despite doing similar levels of outreach, for this sprint, we recieved about 50% of applications than we typically do.
This Google Analytics table shows that of the top 10 countries reached, 7 of them were in the region of Africa and Middle East. Despite Somalia being #4, we did not receive any applications from that country.
Comparatively speaking, for our prior Latin America sprint, we had over 1100 users by the time the sprint report was written. For this event, it was about 50% of that.
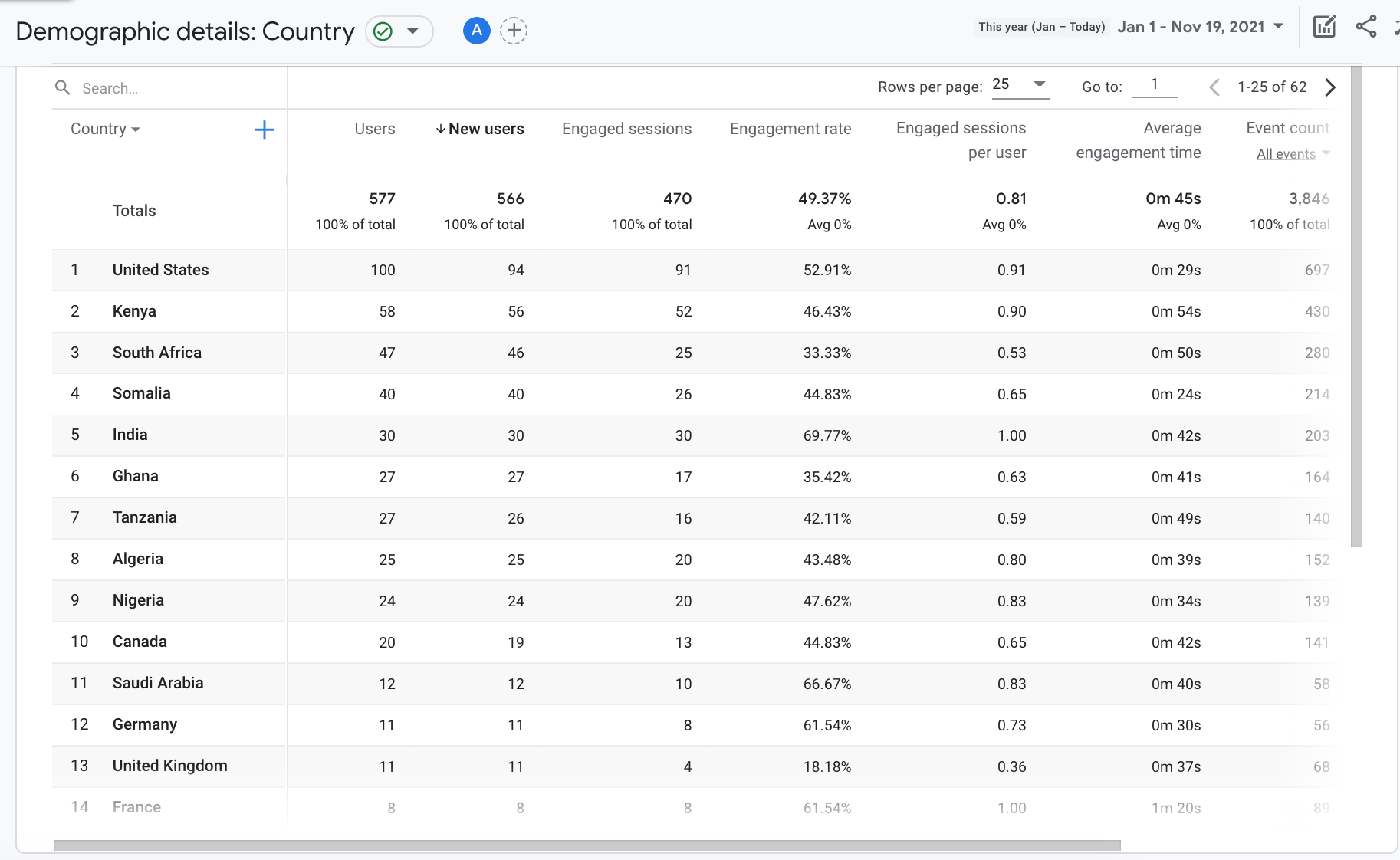
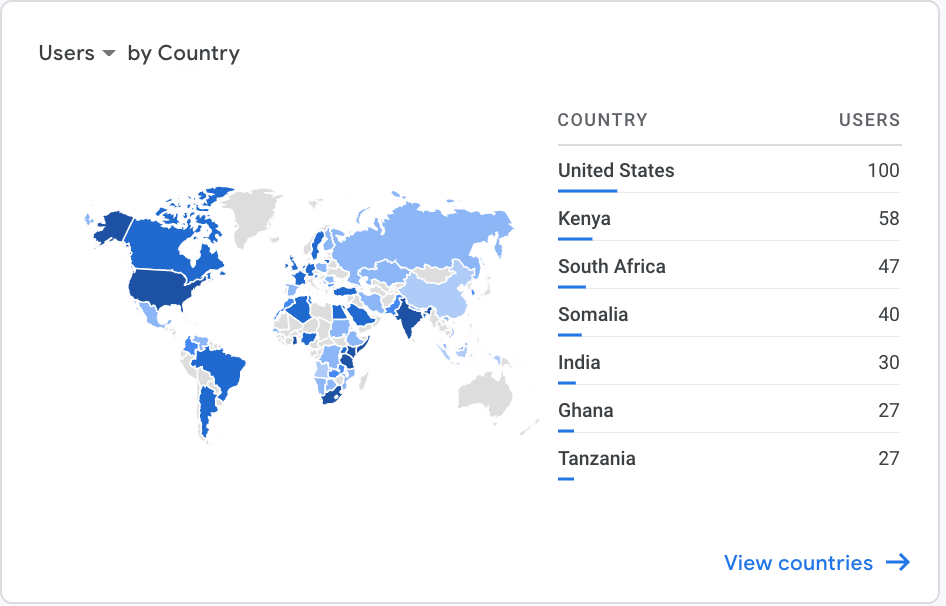
Challenge 2: Preparation Work
Fewer participants in this sprint, compared to past sprints, did their preparation work. A few set up their working environment at the sprint, which results in having less time to work on an issue during the sprint.
One participant commented on the survey that the learning curve for Discord was high. However, the prep work includes watching a 10-minute video Intro to Using Data Umbrella Discord Server.
Challenge 3: Attrition and Impact on Pair Programming
Often with these events, there are no-shows at a rate of 20% to 30%. Pair programming is assigned prior to the sprint. When a participant is a “no-show”, this requires reassigning at the start of the sprint, which delays the start of the sprint. Also, many participants are not proactive in communicating that their pair partner is absent.
Solution: not sure what the solution to this is.
Challenge 4: Internet Connectivity & Electrical Power Access
A number of participants joined intermittently and late due to access with internet connectivity or loss of power.
Continued Contribution to Open Source
Participants were encouraged to keep contributing to scikit-learn or other Python libraries, using the skills learned in this event.
Finding out About the Sprint
For those who attended the sprint, this is how they learned of the event. The main avenues were by invitation from Data Umbrella, Twitter, LinkedIn and their network (“word of mouth”).
Videos
Based on feedback from our last sprint, Latin America 2021, we created a video demonstrating how to use Visual Studio LiveShare.
Language Translations
No new language translations were created for this sprint.
Adjustments for Next Sprint
Returning Contributors
Returning contributors are already in the sprint category on Discord. Work out a process where returning contributors can sign up for the sprint without going through entire application process.
Returning Contributors Working Offline
We received a few requests from past participants to work on issues outside of the sprint day due to schedules. We accommodated that request and they were given access to the curated issues list to work on as their schedule permitted.
Second Co-author on Pull Request
Add in documentation on how to include a second author on pull request commits.
Sprint Feedback
Feedback has been shared a number of ways:
- Twitter Moment
- Blogs
- Sprint survey
- Social media (LinkedIn)
- Casually, in conversation during the sprint, pre-sprint and post-sprint events
Data Umbrella Feedback Survey
Response Rate
The survey response rate was 19/40 = 47.5%. The survey form was in English.
Respondents rated their overall sprint experience highly favorably and had a positive experience working with their pair programming partner.
Favorite Parts About the Sprint
In response to the question “What are your favorite parts about the sprint?”
- Pair programming and the support from the core developers
- Meeting new people and asking the core-developers about issues in our PRs.
- Pair programming. Ability to interact with scikit learn core contributors.
- Pair Programming
- Very quick responses from senior contributors
- I learned a lot, met new people and got a lot of help from the core developers and got to debug things with people.
- The actual sprint day
- The fact we could ask for help in real time from the sklearn contributors team, amazing stuff!
- Working on scikit-learn issues with pair programming partner
- The opportunity to connect with core maintainers; reasonable time commitment
- Hanging out before the sprint and working together
- Working with a new person and tackling an intermediate issue.
- Learning new things and meeting new people.
- Finding a community, getting to meet the sklearn core devs, working together on a contribution
- It was great. Thank you for organizing it.
- Interact with diverse members of the team from different countries.
- It was perfect! Thank you for organizing one.
Suggestions for Improvement
In response to the question “What could have worked better at the sprint?”
- I wish I knew about how to co-author before committing!
- Discord has a bit of a learning curve…
- Maybe a bit more background information on the issue would have been useful. For example why is it an issue, why are the changes necessary, any pertinent guidelines on the scikitlearn best practices, what errors we could expect and general guidelines on how to go about fixing. Of course not all off this information might be known in advance but any background available is always useful :)
- You should do sprints more frequently!
- I think we should have a mechanism in place for putting people that are alone together with existing pairs. Having three people together seems better to me than having some people alone due to internet issues or partners not showing up.
- More time to work on issues.
- Since we are doing everything on Discord, we could also have the kick off meetings on Discord as well. Just makes it easier to attend everything, without having to track different links. But it is just a minor thing, and some people do prefer zoom so there’s that.
- I would have liked to engage more with others, besides my pair programming partner. This way I can easier find somebody to work on in issue beyond the actual event. Maybe improve on the introduction during the zoom meeting to have people interact more relaxed, share things.
Other Feedback from Survey
In response to the question “Include any other thoughts here.”
- This was such an amazing learning experience, especially considering the actual time investment. I hope to continue contributing and to be able to advance to more complex issues along the way.
- I hope that when all the pandemic thing is left behind, and we can return to meeting in person, we keep a couple of virtual sprints thus people like me can attend ^^
- I found it very useful that my pair programming partner pushed me to ask for help on the channel. I think if we haven’t done that I probably would have ended up frustrated and not solving the problems.
- I hope more sprints will be organised.
Sprint: Social Media
Sprint Kickoff
The Africa & Middle East (AFME) #ScikitLearnSprint has kicked off!#python #datascience #machinelearning #oss
— Data Umbrella (@DataUmbrella) October 23, 2021
Wonderful to see returning & new contributors!
Thank you to @codeforsociety & @MooreFound for your support. pic.twitter.com/g7zVivJpPR
First PR Merged!
Reference:https://t.co/Q5WqVVV0Py
— Data Umbrella (@DataUmbrella) October 23, 2021
Fortune of Nigeria / Lithuania
Giancarlo of El Salvador
There's no better way to actually start contributing to open source than a sprint on Scikit-learn 🤭 https://t.co/0vXEE7dyL1
— Giancarlo Pablo (@gpablo06) October 23, 2021
MA of India
My first (and second) open source contribution at @scikit_learn. What an evening it turned out to be. Didn't know it would go so smoothly. Thank you @DataUmbrella
— Mohammad A. (@ma_jauhar) October 23, 2021
Great working with you @miwojcz. See you again in the future sprints 😃#OpenSource #ScikitLearnSprint https://t.co/bo5W6rcLnR
Hannah of Germany
Thank you for making this great sprint happen @reshamas and @DataUmbrella! It was so much fun! #OpenSource #sklearn #womenintech https://t.co/YGBrQmj0ib
— Hannah Bohle (@HannahBohle) October 23, 2021
Maren of Germany
Having fun with @HannahBohle at the #ScikitLearnSprint organised by @DataUmbrella. We're very honoured to be part of this sprint. 😊🎉🥳 #opensource #womenintech pic.twitter.com/uaxtQLNFmP
— Maren Westermann (@MarenWestermann) October 23, 2021
Fortune of Nigeria
Another scikit-learn sprint!😀. Super excited to be a part of this again and experience the fun and challenges of contributing to open source:)). Many thanks to @DataUmbrella, @MooreFound ,@codeforsociety for the opportunity.#opensource #ScikitLearnSprint #python https://t.co/CI1PGbCvLP
— Fortune Uwha🦋 (@fortune_uwha) October 23, 2021
Tia of Zambia
@DataUmbrella gave me the opportunity to attend my first scikit-learn sprint, ever!!! Contributing to this open source library was fun and very educational! - Bonus✨
— Tia (@lontia_nkhuwa) October 30, 2021
Lesson - THE PREP WORK AT ANY SPRINT IS IMPORTANT!! #Python #MachineLearning
Social Media Promotion
Twitter (English)
📣Join us for our #ScikitLearnSprint
— Data Umbrella (@DataUmbrella) September 9, 2021
👉🏽with a focus on Africa & Middle East (AFME)
🗓️23-Oct-2021
🕙 5pm to 9pm EAT
🏢 Online#python #datascience #oss
Thank you to our sponsors: @codeforsociety & @MooreFound
Details on application: https://t.co/UyIoQ9gS2G pic.twitter.com/o9C4PpGg5m
Past Data Umbrella Sprint Reports

Past Data Umbrella Sprint Participant Blogs
Acknowledgments
- All the scikit-learn core contributors who mentored at the sprint and those who were online during the weekend afterwards to promptly review the submitted pull requests.
References
Past Sprint Reports & Blogs by Contributors
- Data Umbrella scikit-learn Sprint Reports
- Past Sprints Blogs by Contributors
Upcoming Sprints
Past Sprints
- List of Past scikit-learn Sprints (scikit-learn wiki)
- List of scikit-learn Sprints (compiled by Reshama Shaikh)
- scikit-learn Sprints Organized by Reshama Shaikh
Code Snippets for Searching GitHub PRs
Data Umbrella PRs from Sprint Day and Later
is:pr #DataUmbrella is:closed sort:updated-desc pr:created:>=2021-10-23
PRs created on sprint day, then sort
is:pr #DataUmbrella created:2021-10-23 sort:updated-desc
Addendum
- [no addendums or updates at the time of publication]


